Module tomotopy
tomotopy 패키지는 Python에서 사용가능한 다양한 토픽 모델링 타입과 함수를 제공합니다.
이 모듈은 c++로 작성되어 컴파일되기 때문에 빠른 속도를 자랑합니다.
tomotopy 란?
tomotopy는 토픽 모델링 툴인 tomoto의 Python 확장 버전입니다. tomoto는 c++로 작성된 깁스 샘플링 기반의 토픽 모델링 라이브러리로,
최신 CPU의 벡터화 기술을 활용하여 처리 속도를 최대로 끌어올렸습니다.
현재 버전의 tomoto에서는 다음과 같은 주요 토픽 모델들을 지원하고 있습니다.
- Latent Dirichlet Allocation (
LDAModel) - Labeled LDA (
LLDAModel) - Partially Labeled LDA (
PLDAModel) - Supervised LDA (
SLDAModel) - Dirichlet Multinomial Regression (
DMRModel) - Hierarchical Dirichlet Process (
HDPModel) - Hierarchical LDA (
HLDAModel) - Multi Grain LDA (
MGLDAModel) - Pachinko Allocation (
PAModel) - Hierarchical PA (
HPAModel) - Correlated Topic Model (
CTModel)
tomotopy의 가장 최신버전은 0.5.1 입니다.
시작하기
다음과 같이 pip를 이용하면 tomotopy를 쉽게 설치할 수 있습니다. (https://pypi.org/project/tomotopy/) ::
$ pip install tomotopy
Linux에서는 c++14 코드를 컴파일하기 위해 gcc 5 이상이 필수적으로 설치되어 있어야 합니다. 설치가 끝난 뒤에는 다음과 같이 Python3에서 바로 import하여 tomotopy를 사용할 수 있습니다. ::
import tomotopy as tp
print(tp.isa) # 'avx2'나 'avx', 'sse2', 'none'를 출력합니다.
현재 tomotopy는 가속을 위해 AVX2, AVX or SSE2 SIMD 명령어 세트를 활용할 수 있습니다.
패키지가 import될 때 현재 환경에서 활용할 수 있는 최선의 명령어 세트를 확인하여 최상의 모듈을 자동으로 가져옵니다.
만약 tp.isa가 none이라면 현재 환경에서 활용 가능한 SIMD 명령어 세트가 없는 것이므로 훈련에 오랜 시간이 걸릴 수 있습니다.
그러나 최근 대부분의 Intel 및 AMD CPU에서는 SIMD 명령어 세트를 지원하므로 SIMD 가속이 성능을 크게 향상시킬 수 있을 것입니다.
간단한 예제로 'sample.txt' 파일로 LDA 모델을 학습하는 코드는 다음과 같습니다. ::
import tomotopy as tp
mdl = tp.LDAModel(k=20)
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
for k in range(mdl.k):
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
tomotopy의 성능
tomotopy는 주제 분포와 단어 분포를 추론하기 위해 Collapsed Gibbs-Sampling(CGS) 기법을 사용합니다.
일반적으로 CGS는 gensim의 LdaModel가 이용하는 Variational Bayes(VB) 보다 느리게 수렴하지만 각각의 반복은 빠르게 계산 가능합니다.
게다가 tomotopy는 멀티스레드를 지원하므로 SIMD 명령어 세트뿐만 아니라 다중 코어 CPU의 장점까지 활용할 수 있습니다. 이 덕분에 각각의 반복이 훨씬 빠르게 계산 가능합니다.
다음의 차트는 tomotopy와 gensim의 LDA 모형 실행 시간을 비교하여 보여줍니다.
입력 문헌은 영어 위키백과에서 가져온 1000개의 임의 문서이며 전체 문헌 집합은 총 1,506,966개의 단어로 구성되어 있습니다. (약 10.1 MB).
tomotopy는 200회를, gensim 10회를 반복 학습하였습니다.
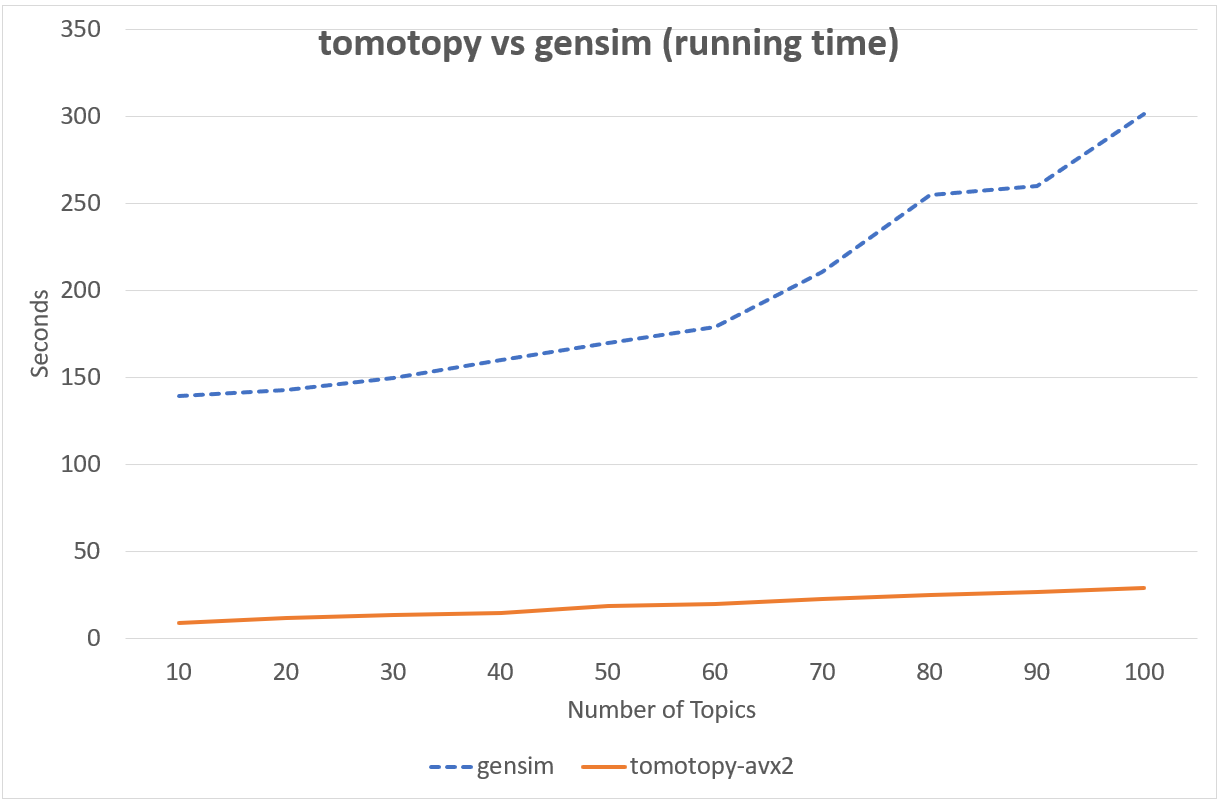
↑ Intel i5-6600, x86-64 (4 cores)에서의 성능
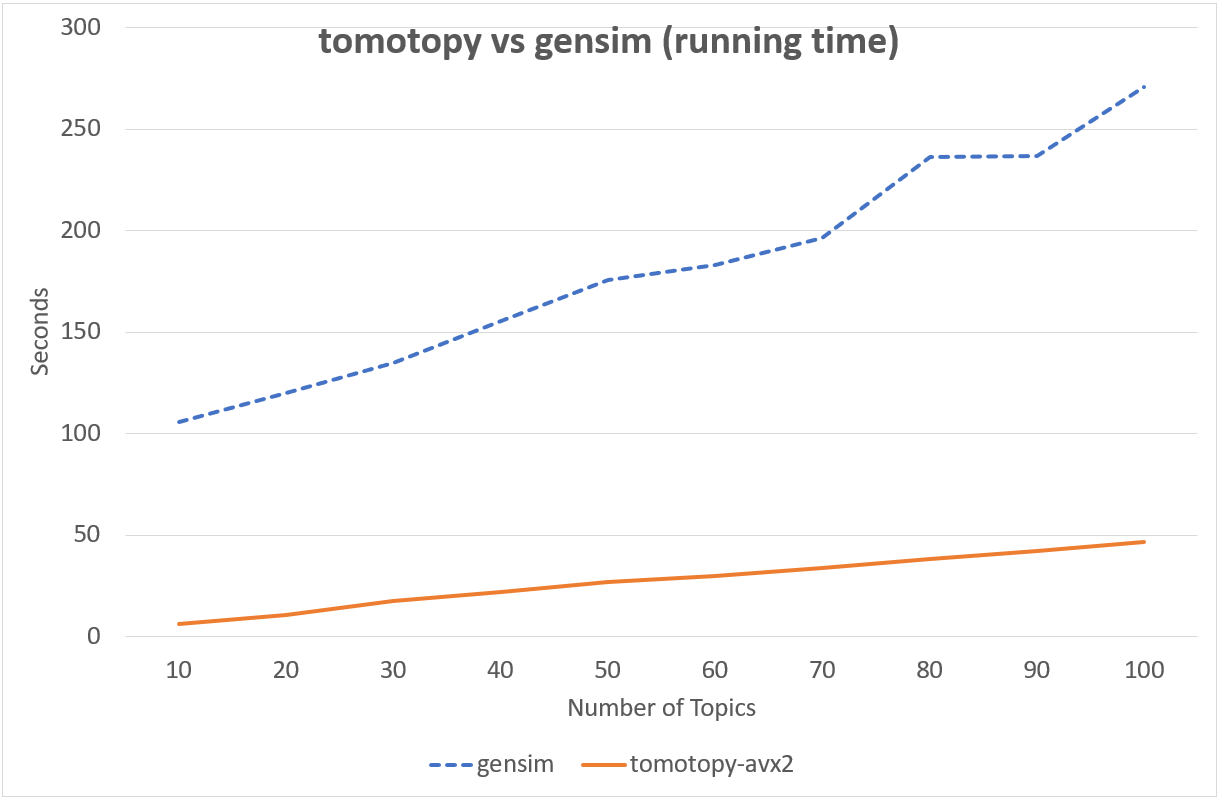
↑ Intel Xeon E5-2620 v4, x86-64 (8 cores, 16 threads)에서의 성능
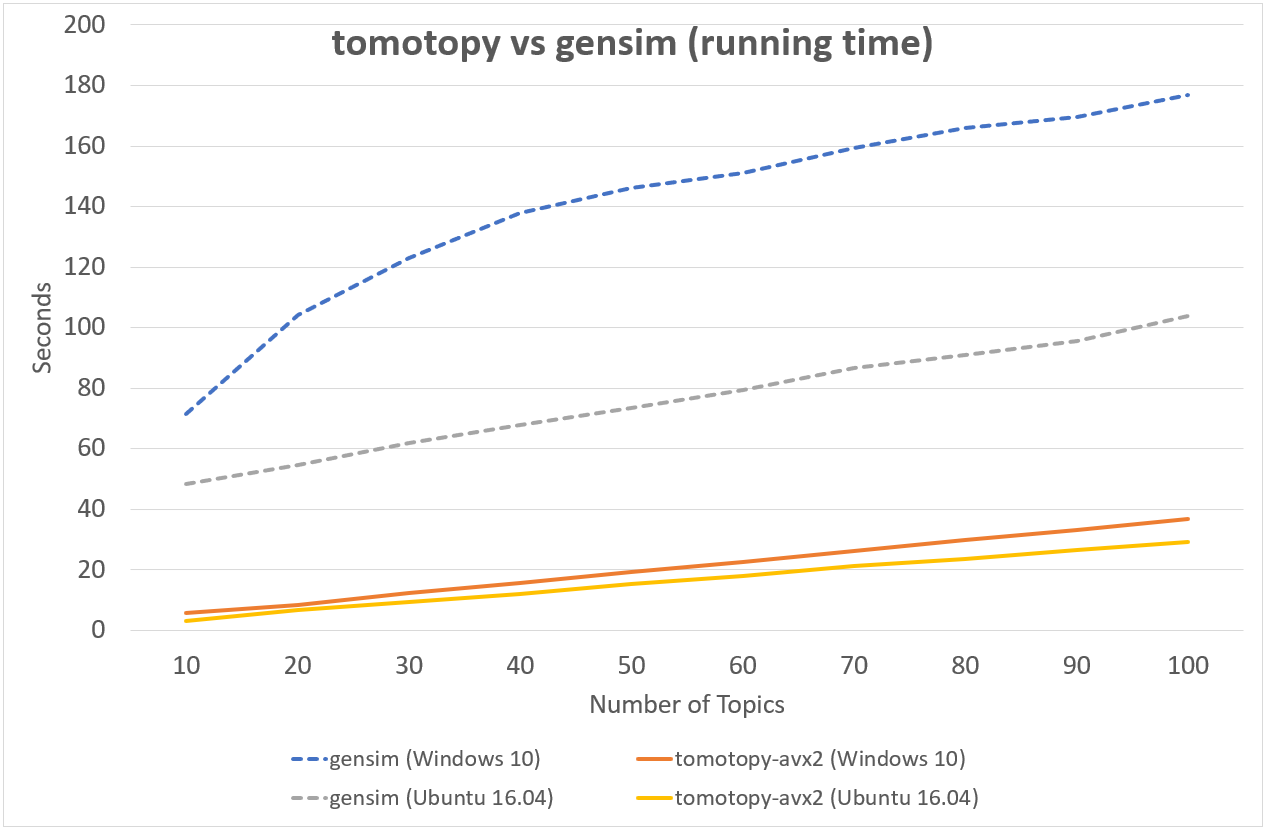
↑ AMD Ryzen7 3700X, x86-64 (8 cores, 16 threads)에서의 성능
tomotopy가 20배 더 많이 반복하였지만 전체 실행시간은 gensim보다 5~10배 더 빨랐습니다. 또한 tomotopy는 전반적으로 안정적인 결과를 보여주고 있습니다.
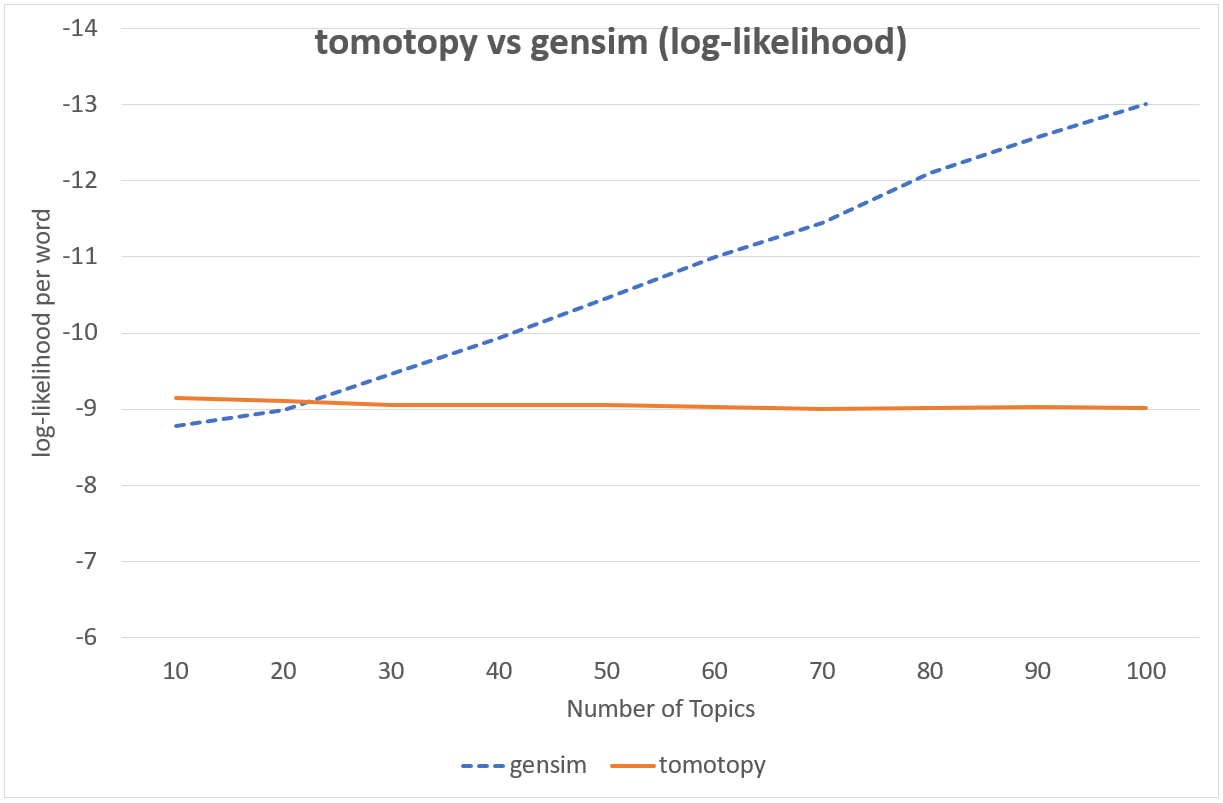
CGS와 VB는 서로 접근방법이 아예 다른 기법이기 때문에 둘을 직접적으로 비교하기는 어렵습니다만, 실용적인 관점에서 두 기법의 속도와 결과물을 비교해볼 수 있습니다. 다음의 차트에는 두 기법이 학습 후 보여준 단어당 로그 가능도 값이 표현되어 있습니다.
| `tomotopy`가 생성한 주제들의 상위 단어 | |
|---|---|
| #1 | use, acid, cell, form, also, effect |
| #2 | use, number, one, set, comput, function |
| #3 | state, use, may, court, law, person |
| #4 | state, american, nation, parti, new, elect |
| #5 | film, music, play, song, anim, album |
| #6 | art, work, design, de, build, artist |
| #7 | american, player, english, politician, footbal, author |
| #8 | appl, use, comput, system, softwar, compani |
| #9 | day, unit, de, state, german, dutch |
| #10 | team, game, first, club, leagu, play |
| #11 | church, roman, god, greek, centuri, bc |
| #12 | atom, use, star, electron, metal, element |
| #13 | alexand, king, ii, emperor, son, iii |
| #14 | languag, arab, use, word, english, form |
| #15 | speci, island, plant, famili, order, use |
| #16 | work, univers, world, book, human, theori |
| #17 | citi, area, region, popul, south, world |
| #18 | forc, war, armi, militari, jew, countri |
| #19 | year, first, would, later, time, death |
| #20 | apollo, use, aircraft, flight, mission, first |
| `gensim`이 생성한 주제들의 상위 단어 | |
|---|---|
| #1 | use, acid, may, also, azerbaijan, cell |
| #2 | use, system, comput, one, also, time |
| #3 | state, citi, day, nation, year, area |
| #4 | state, lincoln, american, war, union, bell |
| #5 | anim, game, anal, atari, area, sex |
| #6 | art, use, work, also, includ, first |
| #7 | american, player, english, politician, footbal, author |
| #8 | new, american, team, season, leagu, year |
| #9 | appl, ii, martin, aston, magnitud, star |
| #10 | bc, assyrian, use, speer, also, abort |
| #11 | use, arsen, also, audi, one, first |
| #12 | algebra, use, set, ture, number, tank |
| #13 | appl, state, use, also, includ, product |
| #14 | use, languag, word, arab, also, english |
| #15 | god, work, one, also, greek, name |
| #16 | first, one, also, time, work, film |
| #17 | church, alexand, arab, also, anglican, use |
| #18 | british, american, new, war, armi, alfr |
| #19 | airlin, vote, candid, approv, footbal, air |
| #20 | apollo, mission, lunar, first, crew, land |
어떤 SIMD 명령어 세트를 사용하는지는 성능에 큰 영향을 미칩니다. 다음 차트는 SIMD 명령어 세트에 따른 성능 차이를 보여줍니다.
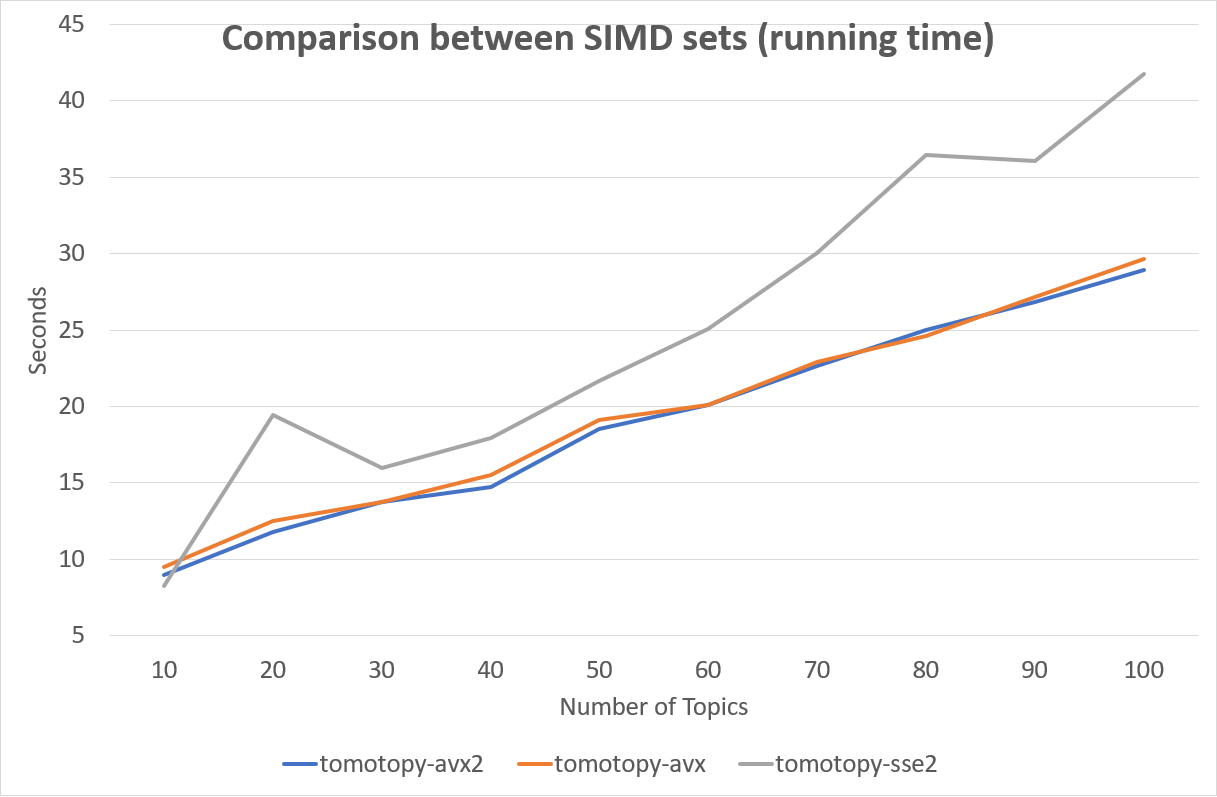
다행히도 최신 x86-64 CPU들은 대부분 AVX2 명령어 세트를 지원하기 때문에 대부분의 경우 AVX2의 높은 성능을 활용할 수 있을 것입니다.
모델의 저장과 불러오기
tomotopy는 각각의 토픽 모델 클래스에 대해 save와 load 메소드를 제공합니다.
따라서 학습이 끝난 모델을 언제든지 파일에 저장하거나, 파일로부터 다시 읽어와서 다양한 작업을 수행할 수 있습니다.
::
import tomotopy as tp
mdl = tp.HDPModel()
for line in open('sample.txt'):
mdl.add_doc(line.strip().split())
for i in range(0, 100, 10):
mdl.train(10)
print('Iteration: {}\tLog-likelihood: {}'.format(i, mdl.ll_per_word))
# 파일에 저장
mdl.save('sample_hdp_model.bin')
# 파일로부터 불러오기
mdl = tp.HDPModel.load('sample_hdp_model.bin')
for k in range(mdl.k):
if not mdl.is_live_topic(k): continue
print('Top 10 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=10))
# 저장된 모델이 HDP 모델이었기 때문에,
# LDA 모델에서 이 파일을 읽어오려고 하면 예외가 발생합니다.
mdl = tp.LDAModel.load('sample_hdp_model.bin')
파일로부터 모델을 불러올 때는 반드시 저장된 모델의 타입과 읽어올 모델의 타입이 일치해야합니다.
이에 대해서는 LDAModel.save()와 LDAModel.load()에서 더 자세한 내용을 확인할 수 있습니다.
모델 안의 문헌과 모델 밖의 문헌
토픽 모델은 크게 2가지 목적으로 사용할 수 있습니다. 기본적으로는 문헌 집합으로부터 모델을 학습하여 문헌 내의 주제들을 발견하기 위해 토픽 모델을 사용할 수 있으며, 더 나아가 학습된 모델을 활용하여 학습할 때는 주어지지 않았던 새로운 문헌에 대해 주제 분포를 추론하는 것도 가능합니다. 전자의 과정에서 사용되는 문헌(학습 과정에서 사용되는 문헌)을 모델 안의 문헌, 후자의 과정에서 주어지는 새로운 문헌(학습 과정에 포함되지 않았던 문헌)을 모델 밖의 문헌이라고 가리키도록 하겠습니다.
tomotopy에서 이 두 종류의 문헌을 생성하는 방법은 다릅니다. 모델 안의 문헌은 LDAModel.add_doc()을 이용하여 생성합니다.
add_doc은 LDAModel.train()을 시작하기 전까지만 사용할 수 있습니다.
즉 train을 시작한 이후로는 학습 문헌 집합이 고정되기 때문에 add_doc을 이용하여 새로운 문헌을 모델 내에 추가할 수 없습니다.
또한 생성된 문헌의 인스턴스를 얻기 위해서는 다음과 같이 LDAModel.docs를 사용해야 합니다.
::
mdl = tp.LDAModel(k=20)
idx = mdl.add_doc(words)
if idx < 0: raise RuntimeError("Failed to add doc")
doc_inst = mdl.docs[idx]
# doc_inst is an instance of the added document
모델 밖의 문헌은 LDAModel.make_doc()을 이용해 생성합니다. make_doc은 add_doc과 반대로 train을 시작한 이후에 사용할 수 있습니다.
만약 train을 시작하기 전에 make_doc을 사용할 경우 올바르지 않은 결과를 얻게 되니 이 점 유의하시길 바랍니다. make_doc은 바로 인스턴스를 반환하므로 반환값을 받아 바로 사용할 수 있습니다.
::
mdl = tp.LDAModel(k=20)
# add_doc ...
mdl.train(100)
doc_inst = mdl.make_doc(unseen_words) # doc_inst is an instance of the unseen document
새로운 문헌에 대해 추론하기
LDAModel.make_doc()을 이용해 새로운 문헌을 생성했다면 이를 모델에 입력해 주제 분포를 추론하도록 할 수 있습니다.
새로운 문헌에 대한 추론은 LDAModel.infer()를 사용합니다.
::
mdl = tp.LDAModel(k=20)
# add_doc ...
mdl.train(100)
doc_inst = mdl.make_doc(unseen_words)
topic_dist, ll = mdl.infer(doc_inst)
print("Topic Distribution for Unseen Docs: ", topic_dist)
print("Log-likelihood of inference: ", ll)
infer 메소드는 Document 인스턴스 하나를 추론하거나 Document 인스턴스의 list를 추론하는데 사용할 수 있습니다.
자세한 것은 LDAModel.infer()을 참조하길 바랍니다.
병렬 샘플링 알고리즘
tomotopy는 0.5.0버전부터 병렬 알고리즘을 고를 수 있는 선택지를 제공합니다.
0.4.2 이전버전까지 제공되던 알고리즘은 COPY_MERGE로 이 기법은 모든 토픽 모델에 사용 가능합니다.
새로운 알고리즘인 PARTITION은 0.5.0이후부터 사용가능하며, 이를 사용하면 더 빠르고 메모리 효율적으로 학습을 수행할 수 있습니다. 단 이 기법은 일부 토픽 모델에 대해서만 사용 가능합니다.
다음 차트는 토픽 개수와 코어 개수에 따라 두 기법의 속도 차이를 보여줍니다.
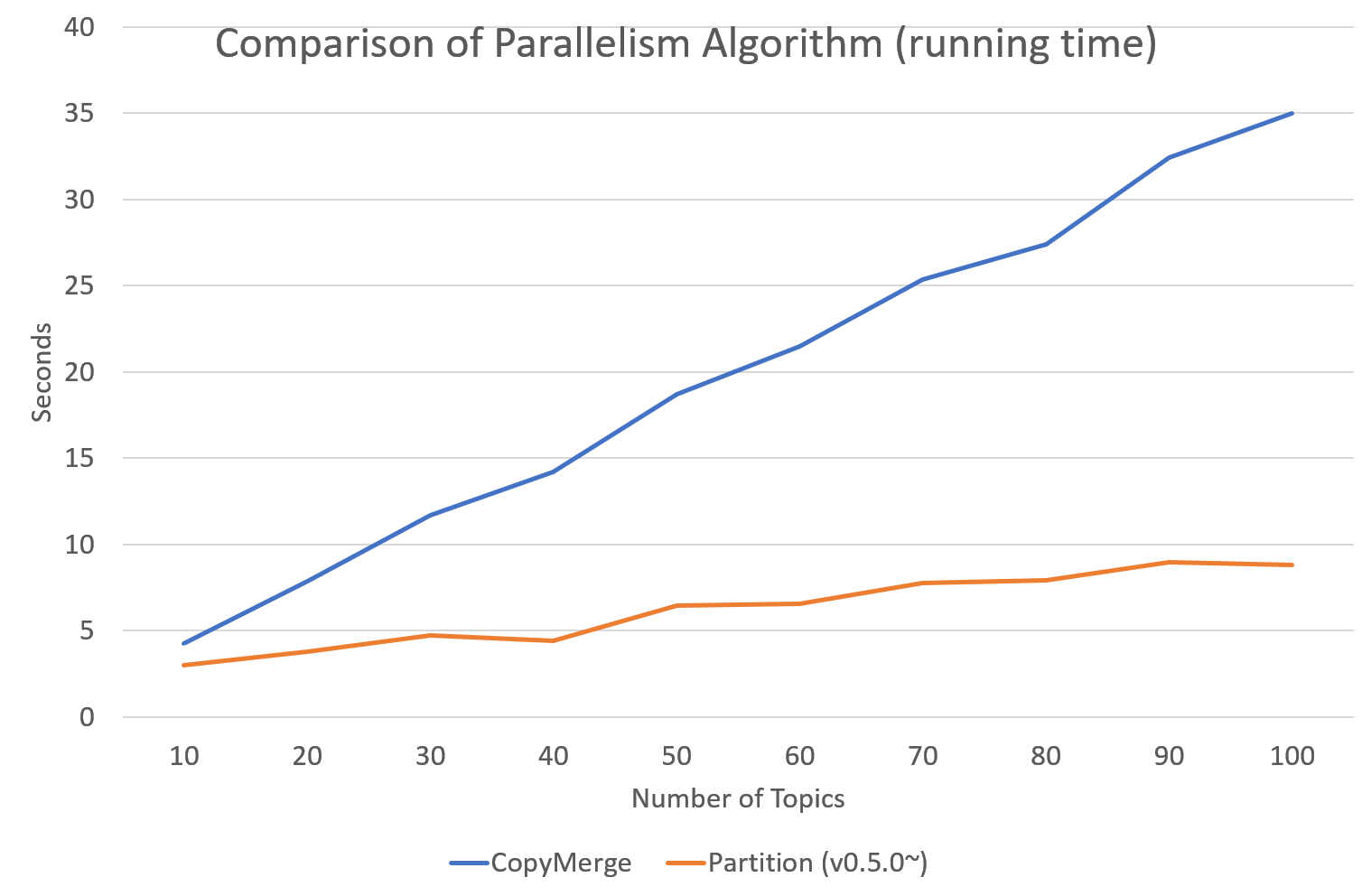
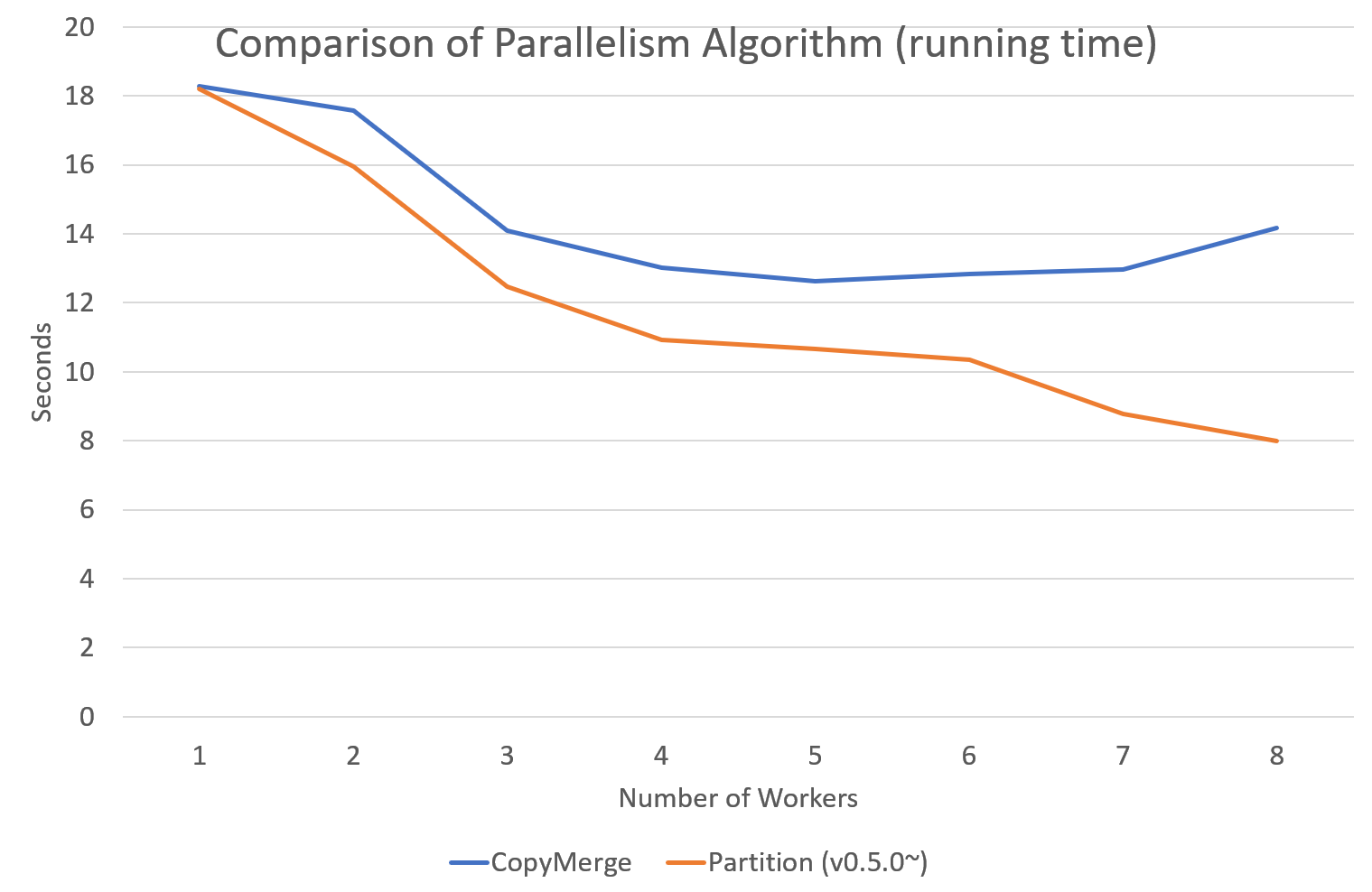
예제 코드
tomotopy의 Python3 예제 코드는 https://github.com/bab2min/tomotopy/blob/master/example.py 를 확인하시길 바랍니다.
예제 코드에서 사용했던 데이터 파일은 https://drive.google.com/file/d/18OpNijd4iwPyYZ2O7pQoPyeTAKEXa71J/view 에서 다운받을 수 있습니다.
라이센스
tomotopy는 MIT License 하에 배포됩니다.
역사
-
0.5.1 (2020-01-11)
SLDAModel.make_doc()에서 결측값을 지원하지 않던 문제를 해결했습니다.SLDAModel이 이제 결측값을 지원합니다. 결측값을 가진 문헌은 토픽 모델링에는 참여하지만, 응답 변수 회귀에서는 제외됩니다.
-
0.5.0 (2019-12-30)
PAModel.infer()가 topic distribution과 sub-topic distribution을 동시에 반환합니다.Document에 get_sub_topics, get_sub_topic_dist 메소드가 추가되었습니다. (PAModel 전용)LDAModel.train()및LDAModel.infer()메소드에 parallel 옵션이 추가되었습니다. 이를 통해 학습 및 추론시 사용할 병렬화 알고리즘을 선택할 수 있습니다.ParallelScheme.PARTITION알고리즘이 추가되었습니다. 이 알고리즘은 작업자 수가 많거나 토픽의 개수나 어휘 크기가 클 때도 효율적으로 작동합니다.- 모델 생성시 min_cf < 2일때 rm_top 옵션이 적용되지 않는 문제를 수정하였습니다.
-
0.4.2 (2019-11-30)
LLDAModel와PLDAModel모델에서 토픽 할당이 잘못 일어나던 문제를 해결했습니다.Document및Dictionary클래스에 가독성이 좋은 __repr__가 추가되었습니다.
-
0.4.1 (2019-11-27)
PLDAModel생성자의 버그를 수정했습니다.
-
0.4.0 (2019-11-18)
-
0.3.1 (2019-11-05)
min_cf혹은rm_top가 설정되었을 때get_topic_dist()의 반환값이 부정확한 문제를 수정하였습니다.MGLDAModel모델의 문헌의get_topic_dist()가 지역 토픽에 대한 분포도 함께 반환하도록 수정하였습니다..tw=ONE일때의 학습 속도가 개선되었습니다.
-
0.3.0 (2019-10-06)
-
0.2.0 (2019-08-18)
-
0.1.6 (2019-08-09)
- macOS와 clang에서 제대로 컴파일되지 않는 문제를 해결했습니다.
-
0.1.4 (2019-08-05)
add_doc메소드가 빈 리스트를 받았을 때 발생하는 문제를 해결하였습니다.PAModel.get_topic_words()가 하위토픽의 단어 분포를 제대로 반환하지 못하는 문제를 해결하였습니다.
-
0.1.3 (2019-05-19)
min_cf파라미터와 불용어 제거 기능이 모든 토픽 모델에 추가되었습니다.
-
0.1.0 (2019-05-12)
- tomotopy의 최초 버전
Expand source code
"""
Python package `tomotopy` provides types and functions for various Topic Model
including LDA, DMR, HDP, MG-LDA, PA and HPA. It is written in C++ for speed and provides Python extension.
.. include:: ./documentation.rst
"""
from enum import IntEnum
class TermWeight(IntEnum):
"""
This enumeration is for Term Weighting Scheme and it is based on following paper:
> * Wilson, A. T., & Chew, P. A. (2010, June). Term weighting schemes for latent dirichlet allocation. In human language technologies: The 2010 annual conference of the North American Chapter of the Association for Computational Linguistics (pp. 465-473). Association for Computational Linguistics.
There are three options for term weighting and the basic one is ONE. The others also can be applied for all topic models in `tomotopy`.
"""
ONE = 0
""" Consider every term equal (default)"""
IDF = 1
"""
Use Inverse Document Frequency term weighting.
Thus, a term occurring at almost every document has very low weighting
and a term occurring at a few document has high weighting.
"""
PMI = 2
"""
Use Pointwise Mutual Information term weighting.
"""
class ParallelScheme(IntEnum):
"""
This enumeration is for Parallelizing Scheme:
There are three options for parallelizing and the basic one is DEFAULT. Not all models supports all options.
"""
DEFAULT = 0
"""tomotopy chooses the best available parallelism scheme for your model"""
NONE = 1
"""
Turn off multi-threading for Gibbs sampling at training or inference. Operations other than Gibbs sampling may use multithreading.
"""
COPY_MERGE = 2
"""
Use Copy and Merge algorithm from AD-LDA. It consumes RAM in proportion to the number of workers.
This has advantages when you have a small number of workers and a small number of topics and vocabulary sizes in the model.
Prior to version 0.5, all models used this algorithm by default.
> * Newman, D., Asuncion, A., Smyth, P., & Welling, M. (2009). Distributed algorithms for topic models. Journal of Machine Learning Research, 10(Aug), 1801-1828.
"""
PARTITION = 3
"""
Use Partitioning algorithm from PCGS. It consumes only twice as much RAM as a single-threaded algorithm, regardless of the number of workers.
This has advantages when you have a large number of workers or a large number of topics and vocabulary sizes in the model.
> * Yan, F., Xu, N., & Qi, Y. (2009). Parallel inference for latent dirichlet allocation on graphics processing units. In Advances in neural information processing systems (pp. 2134-2142).
"""
isa = ''
"""
Indicate which SIMD instruction set is used for acceleration.
It can be one of `'avx2'`, `'avx'`, `'sse2'` and `'none'`.
"""
# This code is an autocomplete-hint for IDE.
# The object imported here will be overwritten by _load() function.
try: from _tomotopy import *
except: pass
def _load():
import importlib, os
from cpuinfo import get_cpu_info
flags = get_cpu_info()['flags']
env_setting = os.environ.get('TOMOTOPY_ISA', '').split(',')
if not env_setting[0]: env_setting = []
isas = ['avx2', 'avx', 'sse2', 'none']
isas = [isa for isa in isas if (env_setting and isa in env_setting) or (not env_setting and (isa in flags or isa == 'none'))]
if not isas: raise RuntimeError("No isa option for " + str(env_setting))
for isa in isas:
try:
mod_name = '_tomotopy' + ('_' + isa if isa != 'none' else '')
globals().update({k:v for k, v in vars(importlib.import_module(mod_name)).items() if not k.startswith('_')})
return
except:
if isa == isas[-1]: raise
_load()
import os
if os.environ.get('TOMOTOPY_LANG') == 'kr':
__doc__ = """`tomotopy` 패키지는 Python에서 사용가능한 다양한 토픽 모델링 타입과 함수를 제공합니다.
이 모듈은 c++로 작성되어 컴파일되기 때문에 빠른 속도를 자랑합니다.
.. include:: ./documentation.kr.rst
"""
__pdoc__ = {}
__pdoc__['isa'] = """현재 로드된 모듈이 어떤 SIMD 명령어 세트를 사용하는지 표시합니다.
이 값은 `'avx2'`, `'avx'`, `'sse2'`, `'none'` 중 하나입니다."""
__pdoc__['TermWeight'] = """용어 가중치 기법을 선택하는 데에 사용되는 열거형입니다. 여기에 제시된 용어 가중치 기법들은 다음 논문을 바탕으로 하였습니다:
> * Wilson, A. T., & Chew, P. A. (2010, June). Term weighting schemes for latent dirichlet allocation. In human language technologies: The 2010 annual conference of the North American Chapter of the Association for Computational Linguistics (pp. 465-473). Association for Computational Linguistics.
총 3가지 가중치 기법을 사용할 수 있으며 기본값은 ONE입니다. 기본값뿐만 아니라 다른 모든 기법들도 `tomotopy`의 모든 토픽 모델에 사용할 수 있습니다. """
__pdoc__['TermWeight.ONE'] = """모든 용어를 동일하게 간주합니다. (기본값)"""
__pdoc__['TermWeight.IDF'] = """역문헌빈도(IDF)를 가중치로 사용합니다.
따라서 모든 문헌에 거의 골고루 등장하는 용어의 경우 낮은 가중치를 가지게 되며,
소수의 특정 문헌에만 집중적으로 등장하는 용어의 경우 높은 가중치를 가지게 됩니다."""
__pdoc__['TermWeight.PMI'] = """점별 상호정보량(PMI)을 가중치로 사용합니다."""
__pdoc__['ParallelScheme'] = """병렬화 기법을 선택하는 데에 사용되는 열거형입니다. 총 3가지 기법을 사용할 수 있으나, 모든 모델이 아래의 기법을 전부 지원하지는 않습니다."""
__pdoc__['ParallelScheme.DEFAULT'] = """tomotopy가 모델에 따라 적합한 병럴화 기법을 선택하도록 합니다. 이 값이 기본값입니다."""
__pdoc__['ParallelScheme.NONE'] = """깁스 샘플링에 병렬화 기법을 사용하지 않습니다. 깁스 샘플링을 제외한 다른 연산들은 여전히 병렬로 처리될 수 있습니다."""
__pdoc__['ParallelScheme.COPY_MERGE'] = """
AD-LDA에서 제안된 복사 후 합치기 알고리즘을 사용합니다. 이는 작업자 수에 비례해 메모리를 소모합니다.
작업자 수가 적거나, 토픽 개수 혹은 어휘 집합의 크기가 작을 때 유리합니다.
0.5버전 이전까지는 모든 모델은 이 알고리즘을 기본으로 사용했습니다.
> * Newman, D., Asuncion, A., Smyth, P., & Welling, M. (2009). Distributed algorithms for topic models. Journal of Machine Learning Research, 10(Aug), 1801-1828.
"""
__pdoc__['ParallelScheme.PARTITION'] = """
PCGS에서 제안된 분할 샘플링 알고리즈을 사용합니다. 작업자 수에 관계없이 단일 스레드 알고리즘에 2배의 메모리만 소모합니다.
작업자 수가 많거나, 토픽 개수 혹은 어휘 집합의 크기가 클 때 유리합니다.
> * Yan, F., Xu, N., & Qi, Y. (2009). Parallel inference for latent dirichlet allocation on graphics processing units. In Advances in neural information processing systems (pp. 2134-2142).
"""
del _load, IntEnum, osGlobal variables
var isa-
현재 로드된 모듈이 어떤 SIMD 명령어 세트를 사용하는지 표시합니다. 이 값은
'avx2','avx','sse2','none'중 하나입니다.
Classes
class CTModel (*args, **kwargs)-
Added in version: 0.2.0
이 타입은 Correlated Topic Model (CTM)의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Blei, D., & Lafferty, J. (2006). Correlated topic models. Advances in neural information processing systems, 18, 147.
- Mimno, D., Wallach, H., & McCallum, A. (2008, December). Gibbs sampling for logistic normal topic models with graph-based priors. In NIPS Workshop on Analyzing Graphs (Vol. 61).
CTModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k=1, smoothing_alpha=0.1, eta=0.01, seed=?)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int- 제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
k:int- 토픽의 개수, 1 ~ 32767 사이의 정수
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var num_beta_sample-
beta 파라미터를 표집하는 횟수, 기본값은 10.
CTModel은 각 문헌마다 총
num_beta_sample개수의 beta 파라미터를 표집합니다. beta 파라미터를 더 많이 표집할 수록, 전체 분포는 정교해지지만 학습 시간이 더 많이 걸립니다. 만약 모형 내에 문헌의 개수가 적은 경우 이 값을 크게하면 더 정확한 결과를 얻을 수 있습니다. var num_tmn_sample-
절단된 다변수 정규분포에서 표본을 추출하기 위한 반복 횟수, 기본값은 5.
만약 결과에서 토픽 간 상관관계가 편향되게 나올 경우 이 값을 키우면 편향을 해소하는 데에 도움이 될 수 있습니다.
var prior_cov-
토픽의 사전 분포인 로지스틱 정규 분포의 공분산 행렬 (읽기전용)
var prior_mean-
토픽의 사전 분포인 로지스틱 정규 분포의 평균 벡터 (읽기전용)
Methods
def get_correlations(self, topic_id)-
토픽
topic_id와 나머지 토픽들 간의 상관관계를 반환합니다. 반환값은LDAModel.k길이의float의list입니다.Parameters
topic_id:int- 토픽을 지정하는 [0,
k), 범위의 정수
Inherited members
class DMRModel (*args, **kwargs)-
이 타입은 Dirichlet Multinomial Regression(DMR) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Mimno, D., & McCallum, A. (2012). Topic models conditioned on arbitrary features with dirichlet-multinomial regression. arXiv preprint arXiv:1206.3278.
DMRModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k=1, alpha=0.1, eta=0.01, sigma=1.0, alpha_epsilon=1e-10, seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
k:int- 토픽의 개수, 1 ~ 32767 범위의 정수.
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
sigma:floatlambdas파라미터의 표준 편차alpha_epsilon:floatexp(lambdas)가 0이 되는 것을 방지하는 평탄화 계수seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var alpha_epsilon-
평탄화 계수 alpha-epsilon (읽기전용)
var f-
메타데이터 자질 종류의 개수 (읽기전용)
var lambdas-
현재 모형의 lambda 파라미터를 보여주는
list(읽기전용) var metadata_dict-
Dictionary타입의 메타데이터 사전 (읽기전용) var sigma-
하이퍼 파라미터 sigma (읽기전용)
Methods
def add_doc(self, words, metadata='')-
현재 모델에
metadata를 포함하는 새로운 문헌을 추가하고 추가된 문헌의 인덱스 번호를 반환합니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable metadata:str- 문헌의 메타데이터 (예로 저자나 제목, 작성연도 등)
def make_doc(self, words, metadata='')-
words단어를 바탕으로 새로운 문헌인Document인스턴스를 반환합니다. 이 인스턴스는LDAModel.infer()메소드에 사용될 수 있습니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable metadata:str- 문헌의 메타데이터 (예를 들어 저자나 제목, 작성연도 등)
Inherited members
class Dictionary (*args, **kwargs)-
list-like Dictionary interface for vocabularies class Document (*args, **kwargs)-
이 타입은 토픽 모델에 사용되는 문헌들에 접근할 수 있는 추상 인터페이스을 제공합니다.
Instance variables
var beta-
문헌의 각 토픽별 beta 파라미터를 보여주는
list(CTModel모형에서만 사용됨, 읽기전용)Added in version: 0.2.0
var labels-
문헌에 매겨진 (레이블, 레이블에 속하는 각 주제의 확률들)의
list(LLDAModel,PLDAModel모형에서만 사용됨 , 읽기전용)Added in version: 0.3.0
var metadata-
문헌의 메타데이터 (
DMRModel모형에서만 사용됨, 읽기전용) var subtopics-
문헌의 단어들이 각각 할당된 하위 토픽을 보여주는
list(PAModel와HPAModel모형에서만 사용됨, 읽기전용) var topics-
문헌의 단어들이 각각 할당된 토픽을 보여주는
list(읽기 전용) var vars-
문헌의 응답 변수를 보여주는
list(SLDAModel모형에서만 사용됨 , 읽기전용)Added in version: 0.2.0
var weight-
문헌의 가중치 (읽기전용)
var windows-
문헌의 단어들이 할당된 윈도우의 ID를 보여주는
list(MGLDAModel모형에서만 사용됨, 읽기전용) var words-
문헌 내 단어들의 ID가 담긴
list(읽기전용)
Methods
def get_sub_topic_dist(self)-
Added in version: 0.5.0
현재 문헌의 하위 토픽 확률 분포를
list형태로 반환합니다. (PAModel전용) def get_sub_topics(self, top_n=10)-
Added in version: 0.5.0
현재 문헌의 상위
top_n개의 하위 토픽과 그 확률을tuple의list형태로 반환합니다. (PAModel전용) def get_topic_dist(self)-
현재 문헌의 토픽 확률 분포를
list형태로 반환합니다. def get_topics(self, top_n=10)-
현재 문헌의 상위
top_n개의 토픽과 그 확률을tuple의list형태로 반환합니다. def get_words(self, top_n=10)-
Added in version: 0.4.2
현재 문헌의 상위
top_n개의 단어와 그 확률을tuple의list형태로 반환합니다.
class HDPModel (*args, **kwargs)-
이 타입은 Hierarchical Dirichlet Process(HDP) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Teh, Y. W., Jordan, M. I., Beal, M. J., & Blei, D. M. (2005). Sharing clusters among related groups: Hierarchical Dirichlet processes. In Advances in neural information processing systems (pp. 1385-1392).
- Newman, D., Asuncion, A., Smyth, P., & Welling, M. (2009). Distributed algorithms for topic models. Journal of Machine Learning Research, 10(Aug), 1801-1828.
0.3.0버전부터
alpha와gamma에 대한 하이퍼파라미터 추정 기능이 추가되었습니다.optim_interval을 0으로 설정함으로써 이 기능을 끌 수 있습니다.HDPModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, initial_k=2, alpha=0.1, eta=0.01, gamma=0.1, seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
initial_k:int- 초기 토픽의 개수를 지정하는 2 ~ 32767 범위의 정수.
0.3.0버전부터 기본값이 1에서 2로 변경되었습니다. alpha:float- document-table에 대한 Dirichlet Process의 집중 계수
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
gamma:float- table-topic에 대한 Dirichlet Process의 집중 계수
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var gamma-
하이퍼 파라미터 gamma (읽기전용)
var live_k-
현재 모델 내의 유효한 토픽의 개수 (읽기전용)
var num_tables-
현재 모델 내의 총 테이블 개수 (읽기전용)
Methods
def is_live_topic(self, topic_id)-
topic_id가 유효한 토픽을 가리키는 경우True, 아닌 경우False를 반환합니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
Inherited members
class HLDAModel (*args, **kwargs)-
이 타입은 Hierarchical LDA 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Griffiths, T. L., Jordan, M. I., Tenenbaum, J. B., & Blei, D. M. (2004). Hierarchical topic models and the nested Chinese restaurant process. In Advances in neural information processing systems (pp. 17-24).
Added in version: 0.4.0
HLDAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, depth=2, alpha=0.1, eta=0.01, gamma=0.1, seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
depth:int- 토픽 계층의 깊이를 지정하는 2 ~ 32767 범위의 정수.
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
gamma:float- Dirichlet Process의 집중 계수
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var depth-
현재 모델의 총 깊이 (읽기전용)
var gamma-
하이퍼 파라미터 gamma (읽기전용)
var live_k-
현재 모델 내의 유효한 토픽의 개수 (읽기전용)
Methods
def children_topics(self, topic_id)-
topic_id토픽의 자식 토픽들의 ID를 list로 반환합니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
def is_live_topic(self, topic_id)-
topic_id가 유효한 토픽을 가리키는 경우True, 아닌 경우False를 반환합니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
def level(self, topic_id)-
topic_id토픽의 레벨을 반환합니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
def num_docs_of_topic(self, topic_id)-
topic_id토픽에 속하는 문헌의 개수를 반환합니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
def parent_topic(self, topic_id)-
topic_id토픽의 부모 토픽의 ID를 반환합니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
Inherited members
class HPAModel (*args, **kwargs)-
이 타입은 Hierarchical Pachinko Allocation(HPA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Mimno, D., Li, W., & McCallum, A. (2007, June). Mixtures of hierarchical topics with pachinko allocation. In Proceedings of the 24th international conference on Machine learning (pp. 633-640). ACM.
HPAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k1=1, k2=1, alpha=0.1, eta=0.01, seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.*
k1: 상위 토픽의 개수, 1 ~ 32767 사이의 정수. k1:int- 상위 토픽의 개수, 1 ~ 32767 사이의 정수
k2:int- 하위 토픽의 개수, 1 ~ 32767 사이의 정수.
alpha:float- 문헌-상위 토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 하위 토픽-단어 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Methods
def get_topic_word_dist(self, topic_id)-
토픽
topic_id의 단어 분포를 반환합니다. 반환하는 값은 현재 하위 토픽 내 각각의 단어들의 발생확률을 나타내는len(vocabs)개의 소수로 구성된list입니다.Parameters
topic_id:int- 0일 경우 최상위 토픽을 가리키며,
[1, 1 +
k1) 범위의 정수는 상위 토픽을, [1 +k1, 1 +k1+k2) 범위의 정수는 하위 토픽을 가리킵니다.
def get_topic_words(self, topic_id, top_n=10)-
토픽
topic_id에 속하는 상위top_n개의 단어와 각각의 확률을 반환합니다. 반환 타입은 (단어:str, 확률:float) 튜플의list형입니다.Parameters
topic_id:int- 0일 경우 최상위 토픽을 가리키며,
[1, 1 +
k1) 범위의 정수는 상위 토픽을, [1 +k1, 1 +k1+k2) 범위의 정수는 하위 토픽을 가리킵니다.
def infer(self, doc, iter=100, tolerance=-1, workers=0, parallel=0, together=False)-
새로운 문헌인
doc에 대해 각각의 주제 분포를 추론하여 반환합니다. 반환 타입은 (doc의 주제 분포, 로그가능도) 또는 (doc의 주제 분포로 구성된list, 로그가능도)입니다.Parameters
doc:DocumentorlistofDocument- 추론에 사용할
Document의 인스턴스이거나 이 인스턴스들의list. 이 인스턴스들은LDAModel.make_doc()메소드를 통해 얻을 수 있습니다. iter:intdoc의 주제 분포를 추론하기 위해 학습을 반복할 횟수입니다. 이 값이 클 수록 더 정확한 결과를 낼 수 있습니다.tolerance:float- 현재는 사용되지 않음
workers:int- 깁스 샘플링을 수행하는 데에 사용할 스레드의 개수입니다. 만약 이 값을 0으로 설정할 경우 시스템 내의 가용한 모든 코어가 사용됩니다.
parallel:intorParallelScheme-
Added in version: 0.5.0
추론에 사용할 병렬화 방법. 기본값은 ParallelScheme.DEFAULT로 이는 모델에 따라 최적의 방법을 tomotopy가 알아서 선택하도록 합니다.
together:bool- 이 값이 True인 경우 입력한
doc문헌들을 한 번에 모델에 넣고 추론을 진행합니다. False인 경우 각각의 문헌들을 별도로 모델에 넣어 추론합니다. 기본값은False입니다.
Inherited members
class LDAModel (*args, **kwargs)-
이 타입은 Latent Dirichlet Allocation(LDA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Blei, D.M., Ng, A.Y., &Jordan, M.I. (2003).Latent dirichlet allocation.Journal of machine Learning research, 3(Jan), 993 - 1022.
- Newman, D., Asuncion, A., Smyth, P., &Welling, M. (2009).Distributed algorithms for topic models.Journal of Machine Learning Research, 10(Aug), 1801 - 1828.
LDAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k=1, alpha=0.1, eta=0.01, seed=?)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
k:int- 토픽의 개수, 1 ~ 32767 범위의 정수.
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Subclasses
Static methods
def load(filename)-
filename경로의 파일로부터 모델 인스턴스를 읽어들여 반환합니다.
Instance variables
var alpha-
하이퍼 파라미터 alpha (읽기전용)
var burn_in-
파라미터 학습 초기의 Burn-in 단계의 반복 횟수를 얻거나 설정합니다.
기본값은 0입니다.
var docs-
현재 모델에 포함된
Document에 접근할 수 있는list형 인터페이스 (읽기전용) var eta-
하이퍼 파라미터 eta (읽기전용)
var k-
토픽의 개수 (읽기전용)
var ll_per_word-
현재 모델의 단어당 로그 가능도 (읽기전용)
var num_vocabs-
작은 빈도의 단어들을 제거한 뒤 남은 어휘의 개수 (읽기전용)
train이 호출되기 전에는 이 값은 0입니다. var num_words-
현재 모델에 포함된 문헌들 전체의 단어 개수 (읽기전용)
train이 호출되기 전에는 이 값은 0입니다. var optim_interval-
파라미터 최적화의 주기를 얻거나 설정합니다.
기본값은 10이며, 0으로 설정할 경우 학습 과정에서 파라미터 최적화를 수행하지 않습니다.
var perplexity-
현재 모델의 Perplexity (읽기전용)
var removed_top_words-
모델 생성시
rm_top파라미터를 1 이상으로 설정한 경우, 빈도수가 높아서 모델에서 제외된 단어의 목록을 보여줍니다. (읽기전용) var tw-
현재 모델의 용어 가중치 계획 (읽기전용)
var vocab_freq-
현재 모델에 포함된 어휘들의 빈도를 보여주는
list(읽기전용) var vocabs-
현재 모델에 포함된 어휘들을 보여주는
Dictionary타입의 어휘 사전 (읽기전용)
Methods
def add_doc(self, words)-
현재 모델에 새로운 문헌을 추가하고 추가된 문헌의 인덱스 번호를 반환합니다.
Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable
def get_count_by_topics(self)-
각각의 토픽에 할당된 단어의 개수를
list형태로 반환합니다. def get_topic_word_dist(self, topic_id)-
토픽
topic_id의 단어 분포를 반환합니다. 반환하는 값은 현재 토픽 내 각각의 단어들의 발생확률을 나타내는len(vocabs)개의 소수로 구성된list입니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
def get_topic_words(self, topic_id, top_n=10)-
토픽
topic_id에 속하는 상위top_n개의 단어와 각각의 확률을 반환합니다. 반환 타입은 (단어:str, 확률:float) 튜플의list형입니다.Parameters
topic_id:int- 토픽을 가리키는 [0,
k) 범위의 정수
def infer(self, doc, iter=100, tolerance=-1, workers=0, parallel=0, together=False)-
새로운 문헌인
doc에 대해 각각의 주제 분포를 추론하여 반환합니다. 반환 타입은 (doc의 주제 분포, 로그가능도) 또는 (doc의 주제 분포로 구성된list, 로그가능도)입니다.Parameters
doc:DocumentorlistofDocument- 추론에 사용할
Document의 인스턴스이거나 이 인스턴스들의list. 이 인스턴스들은LDAModel.make_doc()메소드를 통해 얻을 수 있습니다. iter:intdoc의 주제 분포를 추론하기 위해 학습을 반복할 횟수입니다. 이 값이 클 수록 더 정확한 결과를 낼 수 있습니다.tolerance:float- 현재는 사용되지 않음
workers:int- 깁스 샘플링을 수행하는 데에 사용할 스레드의 개수입니다. 만약 이 값을 0으로 설정할 경우 시스템 내의 가용한 모든 코어가 사용됩니다.
parallel:intorParallelScheme-
Added in version: 0.5.0
추론에 사용할 병렬화 방법. 기본값은 ParallelScheme.DEFAULT로 이는 모델에 따라 최적의 방법을 tomotopy가 알아서 선택하도록 합니다.
together:bool- 이 값이 True인 경우 입력한
doc문헌들을 한 번에 모델에 넣고 추론을 진행합니다. False인 경우 각각의 문헌들을 별도로 모델에 넣어 추론합니다. 기본값은False입니다.
def make_doc(self, words)-
words단어를 바탕으로 새로운 문헌인Document인스턴스를 반환합니다. 이 인스턴스는LDAModel.infer()메소드에 사용될 수 있습니다..Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable
def save(self, filename, full=True)-
현재 모델을
filename경로의 파일에 저장합니다.None을 반환합니다.full이True일 경우, 모델의 전체 상태가 파일에 모두 저장됩니다. 저장된 모델을 다시 읽어들여 학습(train)을 더 진행하고자 한다면full=True로 하여 저장하십시오. 반면False일 경우, 토픽 추론에 관련된 파라미터만 파일에 저장됩니다. 이 경우 파일의 용량은 작아지지만, 추가 학습은 불가하고 새로운 문헌에 대해 추론(infer)하는 것만 가능합니다. def train(self, iter=10, workers=0, parallel=0)-
깁스 샘플링을
iter회 반복하여 현재 모델을 학습시킵니다. 반환값은None입니다. 이 메소드가 호출된 이후에는 더 이상LDAModel.add_doc()로 현재 모델에 새로운 학습 문헌을 추가시킬 수 없습니다.Parameters
iter:int- 깁스 샘플링의 반복 횟수
workers:int- 깁스 샘플링을 수행하는 데에 사용할 스레드의 개수입니다. 만약 이 값을 0으로 설정할 경우 시스템 내의 가용한 모든 코어가 사용됩니다.
parallel:intorParallelScheme-
Added in version: 0.5.0
학습에 사용할 병렬화 방법. 기본값은 ParallelScheme.DEFAULT로 이는 모델에 따라 최적의 방법을 tomotopy가 알아서 선택하도록 합니다.
class LLDAModel (*args, **kwargs)-
이 타입은 Labeled LDA(L-LDA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Ramage, D., Hall, D., Nallapati, R., & Manning, C. D. (2009, August). Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1 (pp. 248-256). Association for Computational Linguistics.
Added in version: 0.3.0
LLDAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k=1, alpha=0.1, eta=0.01, seed=?)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int- 제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
k:int- 토픽의 개수, 1 ~ 32767 범위의 정수.
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var topic_label_dict-
Dictionary타입의 토픽 레이블 사전 (읽기전용)
Methods
def add_doc(self, words, labels=[])-
현재 모델에
labels를 포함하는 새로운 문헌을 추가하고 추가된 문헌의 인덱스 번호를 반환합니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable labels:iterableofstr- 문헌의 레이블 리스트
def get_topic_words(self, topic_id, top_n=10)-
토픽
topic_id에 속하는 상위top_n개의 단어와 각각의 확률을 반환합니다. 반환 타입은 (단어:str, 확률:float) 튜플의list형입니다.Parameters
topic_id:int- 전체 레이블의 개수를
l이라고 할 때, [0,l) 범위의 정수는 각각의 레이블에 해당하는 토픽을 가리킵니다. 해당 토픽의 레이블 이름은LLDAModel.topic_label_dict을 열람하여 확인할 수 있습니다. [l,k) 범위의 정수는 어느 레이블에도 속하지 않는 잠재 토픽을 가리킵니다.
def make_doc(self, words, labels=[])-
words단어를 바탕으로 새로운 문헌인Document인스턴스를 반환합니다. 이 인스턴스는LDAModel.infer()메소드에 사용될 수 있습니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable labels:iterableofstr- 문헌의 레이블 리스트
Inherited members
class MGLDAModel (*args, **kwargs)-
이 타입은 Multi Grain Latent Dirichlet Allocation(MG-LDA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Titov, I., & McDonald, R. (2008, April). Modeling online reviews with multi-grain topic models. In Proceedings of the 17th international conference on World Wide Web (pp. 111-120). ACM.
MGLDAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k_g=1, k_l=1, t=3, alpha_g=0.1, alpha_l=0.1, alpha_mg=0.1, alpha_ml=0.1, eta_g=0.01, eta_l=0.01, gamma=0.1, seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
k_g:int- 전역 토픽의 개수를 지정하는 1 ~ 32767 사이의 정수
k_l:int- 지역 토픽의 개수를 지정하는 1 ~ 32767 사이의 정수
t:int- 문장 윈도우의 크기
alpha_g:float- 문헌-전역 토픽 디리클레 분포의 하이퍼 파라미터
alpha_l:float- 문헌-지역 토픽 디리클레 분포의 하이퍼 파라미터
alpha_mg:float- 전역/지역 선택 디리클레 분포의 하이퍼 파라미터 (전역 부분 계수)
alpha_ml:float- 전역/지역 선택 디리클레 분포의 하이퍼 파라미터 (지역 부분 계수)
eta_g:float- 전역 토픽-단어 디리클레 분포의 하이퍼 파라미터
eta_l:float- 지역 토픽-단어 디리클레 분포의 하이퍼 파라미터
gamma:float- 문장-윈도우 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var alpha_g-
하이퍼 파라미터 alpha_g (읽기전용)
var alpha_l-
하이퍼 파라미터 alpha_l (읽기전용)
var alpha_mg-
하이퍼 파라미터 alpha_mg (읽기전용)
var alpha_ml-
하이퍼 파라미터 alpha_ml (읽기전용)
var eta_g-
하이퍼 파라미터 eta_g (읽기전용)
var eta_l-
하이퍼 파라미터 eta_l (읽기전용)
var gamma-
하이퍼 파라미터 gamma (읽기전용)
var k_g-
하이퍼 파라미터 k_g (읽기전용)
var k_l-
하이퍼 파라미터 k_l (읽기전용)
var t-
하이퍼 파라미터 t (읽기전용)
Methods
def add_doc(self, words, delimiter='.')-
현재 모델에
metadata를 포함하는 새로운 문헌을 추가하고 추가된 문헌의 인덱스 번호를 반환합니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable delimiter:str- 문장 구분자,
words는 이 값을 기준으로 문장 단위로 반할됩니다.
def get_topic_word_dist(self, topic_id)-
토픽
topic_id의 단어 분포를 반환합니다. 반환하는 값은 현재 토픽 내 각각의 단어들의 발생확률을 나타내는len(vocabs)개의 소수로 구성된list입니다.Parameters
topic_id:int- [0,
k_g) 범위의 정수는 전역 토픽을, [k_g,k_g+k_l) 범위의 정수는 지역 토픽을 가리킵니다.
def get_topic_words(self, topic_id, top_n=10)-
토픽
topic_id에 속하는 상위top_n개의 단어와 각각의 확률을 반환합니다. 반환 타입은 (단어:str, 확률:float) 튜플의list형입니다.Parameters
topic_id:int- [0,
k_g) 범위의 정수는 전역 토픽을, [k_g,k_g+k_l) 범위의 정수는 지역 토픽을 가리킵니다.
def make_doc(self, words, delimiter='.')-
words단어를 바탕으로 새로운 문헌인Document인스턴스를 반환합니다. 이 인스턴스는LDAModel.infer()메소드에 사용될 수 있습니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable delimiter:str- 문장 구분자,
words는 이 값을 기준으로 문장 단위로 반할됩니다.
Inherited members
class PAModel (*args, **kwargs)-
이 타입은 Pachinko Allocation(PA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Li, W., & McCallum, A. (2006, June). Pachinko allocation: DAG-structured mixture models of topic correlations. In Proceedings of the 23rd international conference on Machine learning (pp. 577-584). ACM.
PAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k1=1, k2=1, alpha=0.1, eta=0.01, seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int-
Added in version: 0.2.0
제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.*
k1: 상위 토픽의 개수, 1 ~ 32767 사이의 정수. k1:int- 상위 토픽의 개수, 1 ~ 32767 사이의 정수
k2:int- 하위 토픽의 개수, 1 ~ 32767 사이의 정수.
alpha:float- 문헌-상위 토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 하위 토픽-단어 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Subclasses
Instance variables
var k1-
k1, 상위 토픽의 개수 (읽기전용)
var k2-
k2, 하위 토픽의 개수 (읽기전용)
Methods
def get_sub_topic_dist(self, super_topic_id)-
상위 토픽
super_topic_id의 하위 토픽 분포를 반환합니다. 반환하는 값은 현재 상위 토픽 내 각각의 하위 토픽들의 발생확률을 나타내는k2개의 소수로 구성된list입니다.Parameters
super_topic_id:int- 상위 토픽을 가리키는 [0,
k1) 범위의 정수
def get_sub_topics(self, super_topic_id, top_n=10)-
Added in version: 0.1.4
상위 토픽
super_topic_id에 속하는 상위top_n개의 하위 토픽과 각각의 확률을 반환합니다. 반환 타입은 (하위토픽:int, 확률:float) 튜플의list형입니다.Parameters
super_topic_id:int- 상위 토픽을 가리키는 [0,
k1) 범위의 정수
def get_topic_word_dist(self, sub_topic_id)-
하위 토픽
sub_topic_id의 단어 분포를 반환합니다. 반환하는 값은 현재 하위 토픽 내 각각의 단어들의 발생확률을 나타내는len(vocabs)개의 소수로 구성된list입니다.Parameters
sub_topic_id:int- 하위 토픽을 가리키는 [0,
k2) 범위의 정수
def get_topic_words(self, sub_topic_id, top_n=10)-
하위 토픽
sub_topic_id에 속하는 상위top_n개의 단어와 각각의 확률을 반환합니다. 반환 타입은 (단어:str, 확률:float) 튜플의list형입니다.Parameters
sub_topic_id:int- 하위 토픽을 가리키는 [0,
k2) 범위의 정수
def infer(self, doc, iter=100, tolerance=-1, workers=0, parallel=0, together=False)-
Added in version: 0.5.0
새로운 문헌인
doc에 대해 각각의 주제 분포를 추론하여 반환합니다. 반환 타입은 ((doc의 주제 분포,doc의 하위 주제 분포), 로그가능도) 또는 ((doc의 주제 분포,doc의 하위 주제 분포)로 구성된list, 로그가능도)입니다.Parameters
doc:DocumentorlistofDocument- 추론에 사용할
Document의 인스턴스이거나 이 인스턴스들의list. 이 인스턴스들은LDAModel.make_doc()메소드를 통해 얻을 수 있습니다. iter:intdoc의 주제 분포를 추론하기 위해 학습을 반복할 횟수입니다. 이 값이 클 수록 더 정확한 결과를 낼 수 있습니다.tolerance:float- 현재는 사용되지 않음
workers:int- 깁스 샘플링을 수행하는 데에 사용할 스레드의 개수입니다. 만약 이 값을 0으로 설정할 경우 시스템 내의 가용한 모든 코어가 사용됩니다.
parallel:intorParallelScheme-
Added in version: 0.5.0
추론에 사용할 병렬화 방법. 기본값은 ParallelScheme.DEFAULT로 이는 모델에 따라 최적의 방법을 tomotopy가 알아서 선택하도록 합니다.
together:bool- 이 값이 True인 경우 입력한
doc문헌들을 한 번에 모델에 넣고 추론을 진행합니다. False인 경우 각각의 문헌들을 별도로 모델에 넣어 추론합니다. 기본값은False입니다.
Inherited members
class PLDAModel (*args, **kwargs)-
이 타입은 Partially Labeled LDA(PLDA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Ramage, D., Manning, C. D., & Dumais, S. (2011, August). Partially labeled topic models for interpretable text mining. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 457-465). ACM.
Added in version: 0.4.0
PLDAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, latent_topics=0, topics_per_label=1, alpha=0.1, eta=0.01, seed=?)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int- 제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
latent_topics:int- 모든 문헌에 공유되는 잠재 토픽의 개수, 1 ~ 32767 사이의 정수.
topics_per_label:int- 레이블별 토픽의 개수, 1 ~ 32767 사이의 정수.
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var latent_topics-
잠재 토픽의 개수 (읽기전용)
var topic_label_dict-
Dictionary타입의 토픽 레이블 사전 (읽기전용) var topics_per_label-
레이블별 토픽의 개수 (읽기전용)
Methods
def add_doc(self, words, labels=[])-
현재 모델에
labels를 포함하는 새로운 문헌을 추가하고 추가된 문헌의 인덱스 번호를 반환합니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable labels:iterableofstr- 문헌의 레이블 리스트
def get_topic_words(self, topic_id, top_n=10)-
토픽
topic_id에 속하는 상위top_n개의 단어와 각각의 확률을 반환합니다. 반환 타입은 (단어:str, 확률:float) 튜플의list형입니다.Parameters
topic_id:int- 전체 레이블의 개수를
l이라고 할 때, [0,l*topics_per_label) 범위의 정수는 각각의 레이블에 해당하는 토픽을 가리킵니다. 해당 토픽의 레이블 이름은PLDAModel.topic_label_dict을 열람하여 확인할 수 있습니다. [l*topics_per_label,l*topics_per_label+latent_topics) 범위의 정수는 어느 레이블에도 속하지 않는 잠재 토픽을 가리킵니다.
def make_doc(self, words, labels=[])-
words단어를 바탕으로 새로운 문헌인Document인스턴스를 반환합니다. 이 인스턴스는LDAModel.infer()메소드에 사용될 수 있습니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable labels:iterableofstr- 문헌의 레이블 리스트
Inherited members
class ParallelScheme (*args, **kwargs)-
병렬화 기법을 선택하는 데에 사용되는 열거형입니다. 총 3가지 기법을 사용할 수 있으나, 모든 모델이 아래의 기법을 전부 지원하지는 않습니다.
Expand source code
class ParallelScheme(IntEnum): """ This enumeration is for Parallelizing Scheme: There are three options for parallelizing and the basic one is DEFAULT. Not all models supports all options. """ DEFAULT = 0 """tomotopy chooses the best available parallelism scheme for your model""" NONE = 1 """ Turn off multi-threading for Gibbs sampling at training or inference. Operations other than Gibbs sampling may use multithreading. """ COPY_MERGE = 2 """ Use Copy and Merge algorithm from AD-LDA. It consumes RAM in proportion to the number of workers. This has advantages when you have a small number of workers and a small number of topics and vocabulary sizes in the model. Prior to version 0.5, all models used this algorithm by default. > * Newman, D., Asuncion, A., Smyth, P., & Welling, M. (2009). Distributed algorithms for topic models. Journal of Machine Learning Research, 10(Aug), 1801-1828. """ PARTITION = 3 """ Use Partitioning algorithm from PCGS. It consumes only twice as much RAM as a single-threaded algorithm, regardless of the number of workers. This has advantages when you have a large number of workers or a large number of topics and vocabulary sizes in the model. > * Yan, F., Xu, N., & Qi, Y. (2009). Parallel inference for latent dirichlet allocation on graphics processing units. In Advances in neural information processing systems (pp. 2134-2142). """Ancestors
- enum.IntEnum
- builtins.int
- enum.Enum
Class variables
var COPY_MERGE-
AD-LDA에서 제안된 복사 후 합치기 알고리즘을 사용합니다. 이는 작업자 수에 비례해 메모리를 소모합니다. 작업자 수가 적거나, 토픽 개수 혹은 어휘 집합의 크기가 작을 때 유리합니다. 0.5버전 이전까지는 모든 모델은 이 알고리즘을 기본으로 사용했습니다.
- Newman, D., Asuncion, A., Smyth, P., & Welling, M. (2009). Distributed algorithms for topic models. Journal of Machine Learning Research, 10(Aug), 1801-1828.
var DEFAULT-
tomotopy가 모델에 따라 적합한 병럴화 기법을 선택하도록 합니다. 이 값이 기본값입니다.
var NONE-
깁스 샘플링에 병렬화 기법을 사용하지 않습니다. 깁스 샘플링을 제외한 다른 연산들은 여전히 병렬로 처리될 수 있습니다.
var PARTITION-
PCGS에서 제안된 분할 샘플링 알고리즈을 사용합니다. 작업자 수에 관계없이 단일 스레드 알고리즘에 2배의 메모리만 소모합니다. 작업자 수가 많거나, 토픽 개수 혹은 어휘 집합의 크기가 클 때 유리합니다.
- Yan, F., Xu, N., & Qi, Y. (2009). Parallel inference for latent dirichlet allocation on graphics processing units. In Advances in neural information processing systems (pp. 2134-2142).
class SLDAModel (*args, **kwargs)-
이 타입은 supervised Latent Dirichlet Allocation(sLDA) 토픽 모델의 구현체를 제공합니다. 주요 알고리즘은 다음 논문에 기초하고 있습니다:
- Mcauliffe, J. D., & Blei, D. M. (2008). Supervised topic models. In Advances in neural information processing systems (pp. 121-128).
- Python version implementation using Gibbs sampling : https://github.com/Savvysherpa/slda
Added in version: 0.2.0
SLDAModel(tw=TermWeight.ONE, min_cf=0, rm_top=0, k=1, vars='', alpha=0.1, eta=0.01, mu=[], nu_sq=[], glm_param=[], seed=None)
Parameters
tw:intorTermWeight- 용어 가중치 기법을 나타내는
TermWeight의 열거값. 기본값은 TermWeight.ONE 입니다. min_cf:int- 단어의 최소 장서 빈도. 전체 문헌 내의 출현 빈도가
min_cf보다 작은 단어들은 모델에서 제외시킵니다. 기본값은 0으로, 이 경우 어떤 단어도 제외되지 않습니다. rm_top:int- 제거될 최상위 빈도 단어의 개수. 만약 너무 흔한 단어가 토픽 모델 상위 결과에 등장해 이를 제거하고 싶은 경우, 이 값을 1 이상의 수로 설정하십시오. 기본값은 0으로, 이 경우 최상위 빈도 단어는 전혀 제거되지 않습니다.
k:int- 토픽의 개수, 1 ~ 32767 사이의 정수
vars:iterableofstr-
응답변수의 종류를 지정합니다.
vars의 길이는 모형이 사용하는 응답 변수의 개수를 결정하며,vars의 요소는 각 응답 변수의 종류를 결정합니다. 사용가능한 종류는 다음과 같습니다:- 'l': 선형 변수 (아무 실수 값이나 가능)
- 'b': 이진 변수 (0 혹은 1만 가능)
alpha:float- 문헌-토픽 디리클레 분포의 하이퍼 파라미터
eta:float- 토픽-단어 디리클레 분포의 하이퍼 파라미터
mu:floatorlistoffloat- 회귀 계수의 평균값
nu_sq:floatorlistoffloat- 회귀 계수의 분산값
glm_param:floatorlistoffloat- 일반화 선형 모형에서 사용될 파라미터
seed:int- 난수의 시드값. 기본값은 C++의
std::random_device{}이 생성하는 임의의 정수입니다. 이 값을 고정하더라도train시workers를 2 이상으로 두면, 멀티 스레딩 과정에서 발생하는 우연성 때문에 실행시마다 결과가 달라질 수 있습니다.
Ancestors
Instance variables
var f-
응답 변수의 개수 (읽기전용)
Methods
def add_doc(self, words, y=[])-
현재 모델에 응답 변수
y를 포함하는 새로운 문헌을 추가하고 추가된 문헌의 인덱스 번호를 반환합니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable y:listoffloat-
문헌의 응답 변수로 쓰일
float의list.y의 길이는 모델의 응답 변수의 개수인SLDAModel.f와 일치해야 합니다.Added in version: 0.5.1
만약 결측값이 있을 경우, 해당 항목을
NaN으로 설정할 수 있습니다. 이 경우NaN값을 가진 문헌은 토픽을 모델링하는데에는 포함되지만, 응답 변수 회귀에서는 제외됩니다.
def estimate(self, doc)-
doc의 추정된 응답 변수를 반환합니다. 만약doc이SLDAModel.make_doc()에 의해 생성된 인스턴스라면, 먼저LDAModel.infer()를 통해 토픽 추론을 실시한 다음 이 메소드를 사용해야 합니다.Parameters
doc:Document- 응답 변수를 추정하려하는 문헌의 인스턴스 혹은 인스턴스들의 list
def get_regression_coef(self, var_id)-
응답 변수
var_id의 회귀 계수를 반환합니다.Parameters
var_id:int- 응답 변수를 지정하는 [0,
f) 범위의 정수
def get_var_type(self, var_id)-
응답 변수
var_id의 종류를 반환합니다. 'l'은 선형 변수, 'b'는 이진 변수를 뜻합니다. def make_doc(self, words, y=[])-
words단어를 바탕으로 새로운 문헌인Document인스턴스를 반환합니다. 이 인스턴스는LDAModel.infer()메소드에 사용될 수 있습니다.Parameters
words:iterableofstr- 문헌의 각 단어를 나열하는
str타입의 iterable y:listoffloat- 문헌의 응답 변수로 쓰일
float의list.y의 길이는 모델의 응답 변수의 개수인SLDAModel.f와 꼭 일치할 필요는 없습니다.y의 길이가SLDAModel.f보다 짧을 경우, 모자란 값들은 자동으로NaN으로 채워집니다.
Inherited members
class TermWeight (*args, **kwargs)-
용어 가중치 기법을 선택하는 데에 사용되는 열거형입니다. 여기에 제시된 용어 가중치 기법들은 다음 논문을 바탕으로 하였습니다:
- Wilson, A. T., & Chew, P. A. (2010, June). Term weighting schemes for latent dirichlet allocation. In human language technologies: The 2010 annual conference of the North American Chapter of the Association for Computational Linguistics (pp. 465-473). Association for Computational Linguistics.
총 3가지 가중치 기법을 사용할 수 있으며 기본값은 ONE입니다. 기본값뿐만 아니라 다른 모든 기법들도
tomotopy의 모든 토픽 모델에 사용할 수 있습니다.Expand source code
class TermWeight(IntEnum): """ This enumeration is for Term Weighting Scheme and it is based on following paper: > * Wilson, A. T., & Chew, P. A. (2010, June). Term weighting schemes for latent dirichlet allocation. In human language technologies: The 2010 annual conference of the North American Chapter of the Association for Computational Linguistics (pp. 465-473). Association for Computational Linguistics. There are three options for term weighting and the basic one is ONE. The others also can be applied for all topic models in `tomotopy`. """ ONE = 0 """ Consider every term equal (default)""" IDF = 1 """ Use Inverse Document Frequency term weighting. Thus, a term occurring at almost every document has very low weighting and a term occurring at a few document has high weighting. """ PMI = 2 """ Use Pointwise Mutual Information term weighting. """Ancestors
- enum.IntEnum
- builtins.int
- enum.Enum
Class variables
var IDF-
역문헌빈도(IDF)를 가중치로 사용합니다.
따라서 모든 문헌에 거의 골고루 등장하는 용어의 경우 낮은 가중치를 가지게 되며, 소수의 특정 문헌에만 집중적으로 등장하는 용어의 경우 높은 가중치를 가지게 됩니다.
var ONE-
모든 용어를 동일하게 간주합니다. (기본값)
var PMI-
점별 상호정보량(PMI)을 가중치로 사용합니다.